library(bgms)
fit = bgm(Wenchuan, edge_prior = sbm_prior(), chains = 2, seed = 1234)Edge Clustering
In many networks, nodes can be organized in clusters or communities, and edges are not exchangeable. Standard edge priors (Bernoulli, Beta-Bernoulli) cannot encode such structure because they assign the same inclusion probability to every edge. The stochastic block model (SBM) prior embeds the assumption of clustering directly into the graphical model, so that cluster assignments, the number of clusters, and the evidence for clustering are all estimated as part of the analysis (Sekulovski et al., 2025).
The stochastic block model
The SBM (Holland et al., 1983) assumes that each node belongs to one of \(B\) blocks and that the probability of an edge depends on the block membership of its two endpoints. Let \(z_i \in \{1, \dots, B\}\) denote the block assignment of node \(i\). The edge indicators then follow
\[ \gamma_{ij} \mid \boldsymbol{\pi}, \mathbf{z} \sim \text{Bernoulli}(\pi_{z_i z_j}) \]
where \(\pi_{ab}\) is the inclusion probability for edges connecting blocks \(a\) and \(b\). The SBM prior in bgms distinguishes within-block edge probabilities (\(a = b\)) from between-block edge probabilities (\(a \neq b\)), assigning independent Beta priors to each:
\[ \pi_{ab} \sim \begin{cases} \text{Beta}(\alpha_w, \beta_w) & a = b \\[4pt] \text{Beta}(\alpha_b, \beta_b) & a \neq b \end{cases} \]
Setting \(\alpha_w > \beta_w\) and \(\alpha_b < \beta_b\) encodes the expectation that within-cluster connections are dense and between-cluster connections are sparse. When \(B = 1\), the SBM reduces to the standard Beta-Bernoulli prior with hyperparameters \(\alpha_w\) and \(\beta_w\).
The block assignments are modeled using a categorical distribution with prior probability \(P(z_i = b \mid \boldsymbol{\delta}, B) = \delta_b\), where the assignment probabilities \(\boldsymbol{\delta}\) receive a Dirichlet\((\epsilon_1, \dots, \epsilon_B)\) prior with default \(\epsilon_b = 1\). The number of blocks \(B\) is itself a parameter and receives a zero-truncated Poisson prior,
\[ P(B) = \frac{\lambda^B}{B!\,(\exp(\lambda) - 1)}, \quad B \geq 1 \]
with rate \(\lambda\) controlling the expected number of clusters. The rate parameter \(\lambda\) does not exactly equal the expected number of clusters but approximates it: \(\lambda = 1.59\) corresponds to approximately 2 clusters, \(\lambda = 2.82\) to 3, \(\lambda = 3.92\) to 4, and \(\lambda = 4.96\) to 5. For 6 or more expected clusters, \(\lambda\) can be set equal to the expected number of clusters.
In summary, the full hierarchical specification is:
- \(B \sim \text{Poisson}^+(\lambda)\)
- \(\boldsymbol{\delta} \mid B \sim \text{Dirichlet}(\epsilon_1, \dots, \epsilon_B)\)
- \(z_i \mid \boldsymbol{\delta}, B \sim \text{Categorical}(\boldsymbol{\delta})\)
- \(\pi_{ab} \mid B \sim \text{Beta}(\alpha_w, \beta_w)\) for \(a = b\) (within-cluster)
- \(\pi_{ab} \mid B \sim \text{Beta}(\alpha_b, \beta_b)\) for \(a \neq b\) (between-cluster)
- \(\gamma_{ij} \mid \boldsymbol{\pi}, \mathbf{z}, B \sim \text{Bernoulli}(\pi_{z_i z_j})\)
Both \(B\) and \(\boldsymbol{\delta}\) are analytically marginalized out using the Mixtures of Finite Mixtures (MFM) framework (Miller & Harrison, 2018), following the implementation of Geng et al. (2019) for the SBM. This provides consistent estimation of the number of clusters without the sampler ever having to change dimension. For details, see Sekulovski et al. (2025) and, for the technical formulation, Stochastic Block Model Prior.
Setting up the SBM prior
To use the SBM prior, pass sbm_prior() to the edge_prior argument of bgm():
fit = bgm(
x = data,
edge_prior = sbm_prior(),
seed = 1234
)The hyperparameters of sbm_prior() are:
| Argument | Default | Role |
|---|---|---|
alpha, beta |
1, 1 | Beta prior on within-cluster inclusion probability (\(\alpha_w\), \(\beta_w\)) |
alpha_between, beta_between |
1, 1 | Beta prior on between-cluster inclusion probability (\(\alpha_b\), \(\beta_b\)) |
dirichlet_alpha |
1 | Concentration of the Dirichlet prior on block assignments |
lambda |
1 | Rate of the zero-truncated Poisson prior on the number of clusters |
Testing for clustering
Since \(B\) is analytically marginalized out, the MCMC sampler does not produce direct samples of \(B\). Instead, the posterior probability of each number of clusters is computed from the sampled block allocations \(\mathbf{z}\) using the conditional posterior \(P(B = b \mid |\mathcal{C}|)\), where \(|\mathcal{C}|\) is the number of non-empty clusters implied by \(\mathbf{z}\) (see Miller & Harrison, 2018, Eq. 3.7). These posterior cluster probabilities support two types of Bayes factor tests.
Clustering vs. no clustering. The first test compares \(\mathcal{H}_1\!: B > 1\) against \(\mathcal{H}_0\!: B = 1\). The posterior probability of clustering is obtained by summing the posterior probabilities for all \(B > 1\), and the prior odds follow directly from the truncated Poisson: \(\lambda / (\exp(\lambda) - 1 - \lambda)\). A Bayes factor greater than one indicates that the data favor a clustered structure; a Bayes factor less than one indicates evidence for a single-cluster solution. Values near one mean the data do not discriminate — absence of evidence rather than evidence of absence.
Comparing specific cluster counts. The second test compares two point hypotheses — for example \(\mathcal{H}_1\!: B = b_1\) versus \(\mathcal{H}_2\!: B = b_2\) — with prior odds \(\lambda^{b_1 - b_2} \cdot b_2! \,/\, b_1!\). This allows a finer-grained assessment of the evidence for a particular clustering solution.
Both tests are computed from the posterior cluster probabilities returned by extract_sbm() (see below). For the simulation performance and practical recommendations for both Bayes factors, see Sekulovski et al. (2025).
Interpreting block structure
The extract_sbm() function retrieves the clustering results for models fitted with edge_prior = sbm_prior(...):
sbm = extract_sbm(fit)This returns:
posterior_num_blocks: a data frame of posterior probabilities for each number of clusters. These probabilities serve as the basis for computing clustering Bayes factors.posterior_mean_allocations: the estimated cluster assignment for each node, obtained by selecting the allocation that best approximates the average co-clustering structure across MCMC iterations.posterior_mode_allocations: the most frequently occurring cluster assignment across MCMC iterations.posterior_mean_coclustering_matrix: a symmetric matrix where entry \((i, j)\) is the proportion of iterations in which nodes \(i\) and \(j\) were assigned to the same cluster. Coherent blocks indicate stable clusters; diffuse patterns indicate nodes with uncertain membership.
A worked example
Fit the Wenchuan PTSD data with the SBM edge prior (run in advance here; this takes several minutes):
sbm = extract_sbm(fit)
round(head(sbm$posterior_num_blocks, 4), 3) probability
1 0.434
2 0.347
3 0.163
4 0.045The posterior puts most of its mass on one or two clusters. The posterior probability of no clustering (\(B = 1\)) is about 0.43, so the clustering-vs-no-clustering Bayes factor provides no compelling evidence for block structure among these PTSD symptoms — a finding in itself, and a caution against over-reading apparent groupings in the network plot.
The co-clustering matrix tells the same story:
cm = sbm$posterior_mean_coclustering_matrix
p = nrow(cm)
op = par(mar = c(6.5, 6.5, 1, 1))
image(1:p, 1:p, cm[, p:1], col = hcl.colors(20, "Blues", rev = TRUE),
axes = FALSE, xlab = "", ylab = "")
axis(1, at = 1:p, labels = rownames(cm), las = 2, cex.axis = 0.7)
axis(2, at = p:1, labels = colnames(cm), las = 1, cex.axis = 0.7)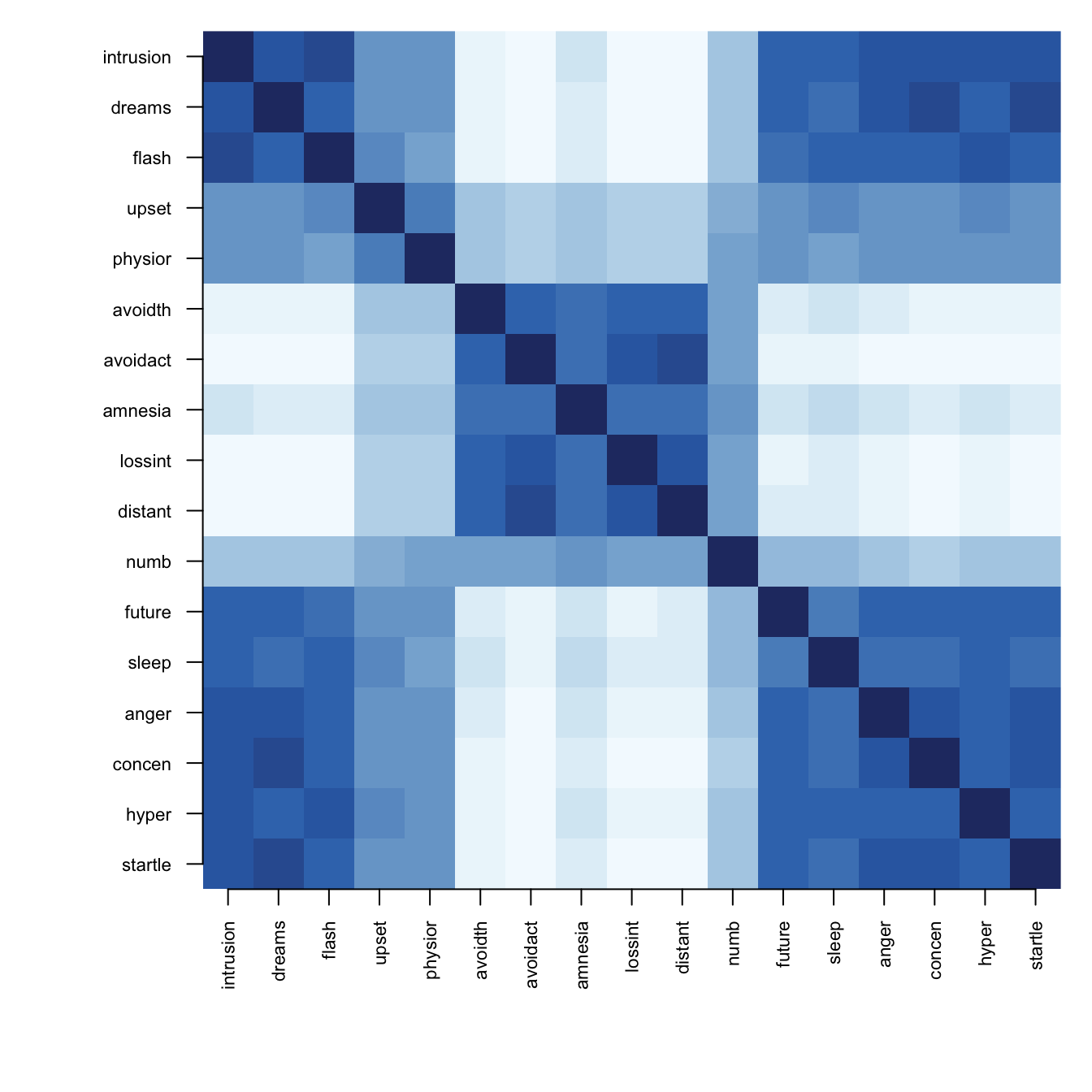
par(op)Most pairs co-cluster in a large share of iterations — consistent with one big cluster rather than separated blocks. In a dataset with real block structure, this plot shows distinct dark diagonal blocks of variables that always cluster together.
Choosing hyperparameters
The choice of hyperparameters encodes how strongly the prior favors a clustered solution and the expected shape of that solution. Sekulovski et al. (2025) provide simulation-based recommendations.
When clustering is expected — set the within-cluster Beta prior to favor dense connections and the between-cluster prior to favor sparse connections:
fit = bgm(
x = data,
edge_prior = sbm_prior(
alpha = 8, beta = 1,
alpha_between = 1, beta_between = 8,
lambda = 1.59
),
seed = 1234
)Here lambda = 1.59 corresponds to a prior expectation of approximately two clusters; higher values shift the expectation toward more clusters (see the \(\lambda\)-to-cluster mapping above).
When no clustering is expected, or the goal is conservative inference that protects against false positive clustering, an informative between-cluster prior combined with flat within-cluster settings provides the best performance:
fit = bgm(
x = data,
edge_prior = sbm_prior(
alpha = 1, beta = 1,
alpha_between = 1, beta_between = 8,
lambda = 1
),
seed = 1234
)This configuration discourages between-cluster edges (\(\beta_b = 8\)), which protects against inferring multiple clusters when only one exists, without imposing strong assumptions about within-cluster density.
The dirichlet_alpha argument of sbm_prior() controls how evenly nodes are distributed across clusters. The default of 1 gives a uniform prior over partitions.
TipTutorial
Sekulovski et al. (2025) provides a step-by-step tutorial on fitting the SBM prior in bgms, including guidance on hyperparameter selection and result interpretation. It is available at https://www.nikolasekulovski.com/blog/post2/.
References
Geng, J., Bhattacharya, A., & Pati, D. (2019). Probabilistic community detection with unknown number of communities. Journal of the American Statistical Association, 114(526), 893–905. https://doi.org/10.1080/01621459.2018.1458618
Holland, P. W., Laskey, K. B., & Leinhardt, S. (1983). Stochastic blockmodels: First steps. Social Networks, 5(2), 109–137. https://doi.org/10.1016/0378-8733(83)90021-7
Miller, J. W., & Harrison, M. T. (2018). Mixture models with a prior on the number of components. Journal of the American Statistical Association, 113(521), 340–356. https://doi.org/10.1080/01621459.2016.1255636
Sekulovski, N., Arena, G., Haslbeck, J. M. B., Huth, K. B. S., Friel, N., & Marsman, M. (2025). A stochastic block prior for clustering in graphical models. Manuscript Submitted for Publication. https://osf.io/preprints/psyarxiv/29p3m_v3